Seeing past the hype: How to think about ‘AI’
12 min read
AI is being thrown around as a broad term to describe many types of automation. In this article we break down and review what the market is calling AI based on several clear defining characteristics. Implementing AI into complex operations also requires careful planning to avoid common pitfalls. We review several such factors to consider when planning for the deployment of AI into business applications.
Technologies applying Artificial Intelligence (AI) are getting a lot of attention in the market. Many would even say we’re near the peak of a hype cycle. Data science efforts within businesses are under pressure to convert data science logic into applications of AI for the business and executives are scrambling to explain how they’re applying AI to their operations.
Looking beyond the general hype and often vague marketing efforts, AI encompasses a very powerful yet nuanced set of technologies. Successfully implementing such advanced technologies requires equally nuanced thinking to yield repeatable benefits and avoid unintended backfires.
Given its breadth and complexity, AI should be though of in a very structured and nuanced way. In this paper, I break down the core factors to consider when applying advanced data science to create AI solutions for use in business operations.
First a semantical note:
I’d be lying if I didn’t admit to the purist in me rolling my eyes a bit the current hyped usage of the term ‘AI’ to describe just about anything linked to even the most basic of automation technologies. Those up to speed on their tech history would be quick to point out that the market has seen several previous AI hype cycles with rampant over-use of the term before things fizzled out.
That said, there’s no question we are going through a period with significant advancement in advanced applications of automation technologies, and particularly automation powered by advanced machine learning logic.
Very little of what today’s market and advertising teams call ‘AI’ is really AI in the pure sense. However, I’ll save the semantical debates for another day. For this article AI will be used, as much of the market is currently using it, to describe a broad spectrum of automation technologies. With that out the way, let’s get into breaking down the different applications of AI.
At the most fundamental level, AI solutions can be broken down into three core axes:
1. How much human interaction is required?
2. What is the basis for the decision logic (pre-defined vs. dynamic mathematics)?
3. What is the price of getting it (the output) wrong?
Let’s take a closer look at each of these:
How much human interaction is required?
– Fully autonomous to suggestive only –
Fully autonomous AI decides and acts on substantive subjects for long periods of time without any direct or indirect human involvement. Such fully autonomous AI often makes the headlines via articles about self-driving cars or NLP engine’s like IBM’s Watson contestant on Jeopardy.
In practice, highly impactful fully autonomous engines are still relatively rare in the current world of things described as being AI. Much of this has to do with the frequently direct relationship between the impactful value of a fully autonomous engine and the price of making a wrong automated decision—a subject which we’ll cover in the next section.
At the other end of the spectrum we find technologies that may initially act autonomously, but where the final decision or action still relies on a human. A common example here is advanced search functionality. When you search for something advanced autonomous engines present back a list of calculated relevant results, but the human still makes the final selection.
Even with the “I’m feeling lucky” search button the human still evaluates the resulting page to make a final determination of if this is what they’re looking for before taking any subsequent action. This final human evaluation in the decision tree is a practical solution to the reality of technologies in this corner of AI—they’re very powerful and add a lot of value, but still not quite good enough to take the human out of the final decision loop.
This subtle simple circuit-breaker in the implementation is a key safeguard to deploying advanced AI into many applications. It is unlikely these technologies would have achieved broad adoption without it—with automated missteps quickly annoying users more than the minor impact of asking the user to make the final call.
What is the price of getting it wrong?
– From minor annoyance up to, possibly, death –
No AI is perfect and while there is an ever-increasing number of areas where AI technologies are able to perform as good as or better than humans in terms of speed and accuracy mistakes can and will happen. In fact, because most AI approaches rely on complex mathematical relationships behind the scenes vs. truly adaptive experiential logic (i.e., how most humans ‘think’) wrong outputs from an AI are sometimes not just wrong but spectacularly wrong. So wrong that a human often struggles to understand why the AI didn’t see that this was obviously completely wrong.
It may be obviously wrong to a human applying adaptive logic (“yes its fury and vaguely looks like a dog but that’s obviously not real and is a child’s stuffed animal toy”), but based on the mathematical logic of an algorithm it’s still the best answer (“based on the historical training of my neural network, which only included real animals, the most likely answer for what’s in this image is a dog”).
Thus when integrating AI technologies into any operational system it’s not a question of “will it get it wrong” but rather “what’s the price when the AI does get it wrong?” This, probably more than anything else, is the biggest hurdle for technologies seeking to be fully autonomous AI.
IBM Watson’s Jeopardy contestant performed quite well, but did sometimes get it wrong. However the price of those errors, some points on a game show, was fairly low. Autonomous vehicles have an extremely high price of getting it wrong. At this extreme end self-driving AIs that make mistakes can and have killed people.
Considering these risks is critical to implementing AI technologies without unforeseen negative consequences. In practice, many implementations back off the ‘fully autonomous’ aspect just a bit to put a human in the loop. For example, Tesla is careful to note that while its autopilot feature does essentially result in a self-driving car “Current Autopilot features require active driver supervision and do not make the vehicle autonomous.” The cost of getting it wrong is just too high to let the human off the hook.
A high price of getting it wrong doesn’t mean we avoid the technology—there’s a price to not taking these approaches too—but it does mean that we need a very carefully planned mechanism for dealing with these failures that will inevitably occur.
What is the basis for the decision logic?
– From answers pre-defined by humans to superiority decided mathematically –
Mechanisms relying on pre-defined logic follow a structured logical tree, typically laid out by the humans that designed the system. If A then B. The robotic process automation (RPA) sphere heavily relies on this sort of decision logic. Such approaches can be very powerful and useful in scenarios where the inputs and possible outputs are well defined and consistent. However, in more dynamic environments pre-defined logical approaches struggle to adapt simply because it’s not possible to pre-program all possible scenarios.
At the other extreme, mechanisms relying on purely mathematical logic assess the input data based on a mathematical model that decides output based on the mathematical superiority of one answer over another. A human has not defined each possible input/output and may not even have a very good understanding of exactly how the decision logic is occurring. Many AI engines taking this approach rely on multi-layered machine learning models (aka neural networks) that leverage multi-dimensional numerical matrices to represent the underlying data.
Such mathematical models do not need have all possible paths pre-defined. A neural network that decides if an image of a face is the same person as a photograph in a database is an example of a model relying on mathematical logic. Such systems can be incredibly powerful in adapting to fuzzier inputs, but are also unavoidably and inherently biased by their historical training. If an input falls outside of the realm of previous training sets the model outputs, and hence AI actions, can be easily fooled into incorrect decisions (e.g., the earlier example of mistaking a stuffed animal toy for an actual dog because the model was biased into only knowing what real animals looks like).
The complexity of such models also creates challenges for explaining why one answer was chosen over another. A whole sub-branch of machine learning is dedicated to creating better transparency around complex models to highlight why an answer was chosen. For example, image recognition algorithms can be enhanced to show what part(s) of the image were considered the key features to identify an object as X, which is key to catching scenarios when the algorithm is making decisions based on the wrong part of an image.
One could argue that these mathematical models are just fancier version of pre-defined logic as a human still designed the, albeit complex, logic applied and the training sets used. That’s true, although the core differentiator here is if the ultimate decision logic was pre-assigned by a human in a logical tree vs. if the decisions is based on a calculated mathematical superiority over others without pre-programing all possible pathways.
Mapping AI Applications
Bringing those three core factors together we start to see clear differentiation across the many different technology applications being labeled as AI:
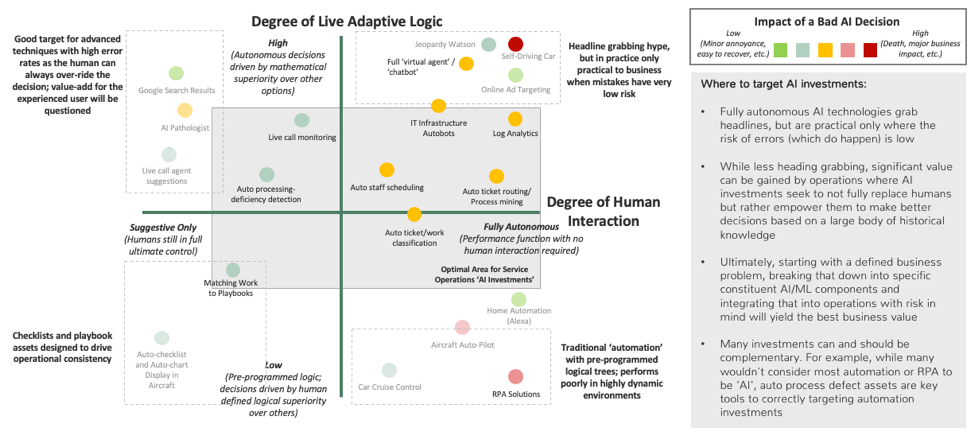
Multi-dimensional overview of applied AI technologies
The sweet spot for most AI developments inside complex businesses is currently somewhere in the middle. Fully autonomous approaches are flashy, but often still too risky or problematic to implement without any human intervention. Similarly, 100% pure ML-based decision logic often still needs some human-derived supplemental logic to best fit available business use cases—often just simply in the form of defined circuit breakers in the decision logic to guard against models proposing answers outside a designated zone.
Basic automation, the sort of thing that was broadly in use long before the current AI craze, is still very much a thing. While marketing teams often label things in this space as AI, in practice advanced data science teams are typically not required to get value out of these mainstay approaches.
Of course it’s hard to fully distill such a complex world down into a simple chart and there are other core factors to consider beyond those discussed already. While the previous factors broadly define a breakdown of different AI solutions, the remainder of this article focuses on some additional critical factors that must be considered when developing and applying AI to both ensure value for business stakeholders and to avoid potentially painful missteps. Such factors include:
- – Input errors and how to deal with them
- – The Inverse Human Involvement model
- – Are you human? (the transparency of AI approaches)
- – User Empathy / User EQ in AI applications
Input errors and how to deal with them
In considering the original three factors, there’s a general assumption that the input data is of good quality and thus our focus is on the model/AI engine, but of course in the real world one often needs to deal with data of questionable quality—often on the fly as data is streaming in from logs or sensors.
A set of streaming log files could be corrupted or stop flowing. Camera or positional sensors could be blocked or transmitting bogus data. Models that just assume the data must be good without any alternative backups are at high risk of unforeseen catastrophic failure. How to address such scenarios is a key component of successfully implementing AI technologies in real-word scenarios.
Sometimes it’s best to just have the AI admit defeat and simply say it doesn’t know what’s going on vs. plowing forward—a reasonable solution unless the AI use case is for it to be completely autonomous. At a minimum, the AI needs to have some reasonable mechanism for detecting and acting upon the fact that something is off with the input data. This requires careful planning and testing. Humans, with our analog adaptive logic, have a strong innate ability to detect that something feels a bit ‘off.” Computers and their binary digital logic very much lack this native intuition.
Getting this seemingly simple issue wrong can have catastrophic consequences. The recent example of the Boeing 737-MAX crashes highlights what can go wrong when AI automation relies on bad sensor data without automatically being able to adequately identify and suppress the anomaly. While current reports are still preliminary, published evidence suggests that the automation in this case (called MCAS) was relying on data from a single faulty angle-of-attack sensor with the computer believing the aircraft was approaching an aerodynamic stall. The automation responded with drastic and forceful flight control inputs to avoid a situation that was in fact not actually occurring. Early reports have been critical of a design that relied on a single sensor for such a key measurement, with limited ability to automatically detect that this key input data into the model might be wrong.
In implementing AI within operations, teams must plan for the possibility that the input data is simply wrong. This is especially important with systems seeking to be more autonomous as there’s more likelihood for automated decisions to have negative impacts before a human figures out something is off and intervenes.
Beyond the obvious cases, such as input data that stops flowing, well-designed AI models need to be continuously assessing and cross-checking the quality of input data to monitor for any unusual behavior. Factors such as entity recognition are also key features of well-designed AI models, especially where the data feeds are more unstructured. For example, many models that leverage natural language processing (NLP) are easily thrown off track if they just blindly analyze any free text data thrown into the model. Such free text is often polluted with other inputs—such as pasted log files, e-mail headers or other content—that needs to be first identified and handled accordingly before proceeding with the NLP aspects of a broader AI model.
Inverse Human Involvement
Revisiting our level of human interaction axis for a moment, there’s another nuanced version of this where the human involvement is inverted—the human is normally fully in control unless the machine thinks the human has made a mistake. The AI’s intervention can range from simple alerts to a full instant takeover of decisions and resulting actions.
Returning to our 737-MAX example again the design of the MCAS system follows this inverse human involvement model. Pilots were in control of the airplane, but if the AI felt the pilots may have done something wrong the AI could automatically step in and take over the controls (in this case pushing the nose of the plane downwards). Cars with automatic braking technology also take a similar approach, slamming on the brakes if proximity sensors believe you’re about to hit something and are not already braking enough to stop in time.
Such approaches can provide powerful risk mitigation enhancements to dynamic environments, especially situations like driving or flying where the human could become distracted and miss something small that’s about to become something big. Similar approaches can also be used to enhance service quality and efficiency.
However, the question of “what if the AI is wrong?” still can’t be ignored—an AI overriding a human for a ‘mistake’ that isn’t really happening can quickly spiral a risk mitigation engine into a risk generating one.
With the 737-MAX, preliminary reports indicate that the pilots in both crashes experienced difficulty in overriding the inverse human involvement AI logic when it was clear the AI was inappropriately trying to take over control of the aircraft. Various points of view have been presented on the reasons for the difficulty in overriding the system ranging from potential gaps in training, communication on system features or the overall design of the system logic. Regardless of the reasons in that particular case, being able to quickly override false triggers is key to any inverse human involvement system design.
There’s no simple universal solution to addressing the risk of false triggering in the inverse human involvement AI model and broadly speaking such approaches do a lot of good. I’d prefer driving a car with auto-braking vs. one without, and the small plane I pilot includes “envelope protection” automation that will automatically push the controls forward while a computer voice yells in your ear if the automation believes the plane is about to stall. However, whether it’s on sophisticated machinery or business process management, teams implementing AI technologies under the inverse involvement model need to very carefully think about and test around scenarios where the automatic intervention is in fact incorrect.
Ideally the human needs enough time and ability easily to override a bad decision before that decision has significant negative consequences. If that’s not practical, then teams should consider interventions that have softer or escalating impacts—such as providing a series of warnings prior to finally just taking over and overtaking the human.
Are you a human?
When implementing AI approaches teams need to think about if the humans operating around or with the such technologies know, or are even told, that they are actually interacting with an AI. This also quickly introduces a broad range of important ethical questions too. Such ethical discussions would take up a whole book, so below we will only focus on the operational aspects of AI-human interactions. Full blown Turing Test busting AIs in business are certainly intriguing, but silently deploy them at your peril. If it’s business value and improved customer experience you’re after a bit more nuanced planning and integration thinking is needed.
Headlines promote stories about service desks being replaced with AI virtual agents that remove the need for humans to staff the desk or chatbots that address your every need. In practice such efforts have seen more limited success, with the most broadly adapted and successful implementations of such technologies following a similar pattern—specifically that they don’t try to fool the human to think that they’re interacting with another human. Instead the most successful approaches tend to take a ‘command and control’ approach to human interaction.
The illusion of AIs pretending to be humans frequently breaks down quickly, with the human on the other end rapidly becoming annoyed. “Human!” “Agent!” “0 0 0 0 0 0” Whatever savings that may have been achieved by replacing a human with an AI-assistant can quickly be lost several-fold over in the form of reduced customer satisfaction and, ultimately, lost business.
The command and control approach has a much more successful track record of human-AI relations. Alexa, Siri and other interactive assistants are strong examples of successful command and control models. I know my Alexa isn’t a human, and I don’t attempt to interact with it as such. Rather, I know that if I speak to it with a series of command and control interactions—“Alexa, play WNYC FM”—the AI will react and do what I want. Search engines are also another form of command and control AI.
Applying this concept more broadly, AI integrated into business operations will be most successful if those working around the AI know it’s there and know how to interact with it and get value from it. If you just showed a non-user an Echo Dot and said “this is an AI, it’s amazing” then walked out of the room they’d probably quickly grow frustrated with this odd system. However, with some quick training and understanding of how to interact with it, users of all ages and computing experience levels can quickly get value from the AI. We shouldn’t forgot such basics when deploying any other types of AI elsewhere.
User Empathy / User EQ
Lastly, overarching all of the other considerations is the often-overlooked fundamental question of how the AI technology will be used, or loathed, by the humans asked to interact with it. This is often a general challenge for all data science teams as there is often a gap between what such teams find interesting and what will provide true value to stakeholders and users. This is frequently referred to as the need for teams to have user empathy or a high user EQ.
Teams with low user EQ can become so entrenched in the technical and mathematical aspects of developing an advanced model or approach that they completely forget to think about if anyone really cares about what was just done.
The ‘care’ bit here being a key part of the skill behind ‘user EQ.’ Yes, fellow data scientists might care a lot about the novel mathematics behind a new model or the fact that this AI performs better against some benchmark, but successful applications of data science require more than just good data science. We also need to think about how the output of what we’re doing will integrate into the broader universe, which typically means integrating with a complex network of established systems and processes.
The AI needs to add clear value for stakeholders. Something that’s ‘really cool’ will hit a brick wall quite quickly if it’s fundamentally just not all that useful to the target users. Also, AI is not some magic fix-all for every scenario. Sometimes a simple manual adjustment is all that is needed, and it takes a skilled and confident data science leader to say so.
Adding value to an operation also typically means successfully integrating the AI technology into a complex network of existing processes and practices. If the AI does X better than the existing process for X, how will these two processes relate or interact. Data science teams often would prefer that operations simply dump the old way and just drop in the new way, but this is typically not practical or desirable for a range of reasons. Teams with high user EQ will think about and develop ways to improve the process for X by carefully integrating value-add improvements while respecting the many other factors that determine why existing processes are the way they are.
Having a solid user EQ requires close working collaboration with operational leaders and subject matter experts to ensure that AI assets return maximum value. Developing user EQ is a key component of a modern ‘full stack’ data scientist—a topic which will get explored further in a later article.
If everything above is taken into account and the effort has strong user EQ then the most oblivious sign of success is that the target users and stakeholders for the AI quickly become its greatest ambassadors. The best solutions will easily sell themselves. If your team feels like it’s trying to push an amazing solution onto stakeholders check your user EQ—you’re probably missing something!
Nicholas Hartman is the Chief Innovation Officer at CKM Analytix